[Yubarta devlog #001] What I'm building and why
Yubarta 🐋 is my new side project. It’s a self-healing tool for automating the remediation of servers at scale. It triggers actions across a fleet of machines based on third-party alerts (like Grafana or Datadog) or on custom eBPF programs remotely injected into your servers’ kernels. It’s event-driven, programmable, agentless, and infrastructure-agnostic. This is one of my toy projects — but I’m taking it seriously.
Link to repo: https://github.com/dfrojas/yubarta
Motivation
Yubarta isn’t just about remediation logic — it’s also my way of going deep into systems I’ve used but never fully dissected. I want to understand more about how Kafka handles consumer lag, offset commits, and partition rebalancing under pressure — and use eBPF to trace where the lag is really coming from, down to syscalls or blocking socket reads. On the Postgres side, I want to generate flamegraphs of slow queries, observe vacuum behavior under write-heavy loads, explore MVCC internals, and measure the real-world impact of index bloat and visibility maps and how to create Gen AI Agents. Even the YAML pipeline is a way to play with schema validation, AST generation, and sandboxed rule evaluation.
It’s not a commercial product. Yubarta exists purely out of curiosity — built for fun and learning. Everything in Yubarta is a pretext to learn. The more complex the internals, the more interesting it becomes.
Tech Stack
The stack isn’t minimal — and that’s on purpose. This project is about exploration.
Yubarta is written in Python, with FastAPI powering the API and pure Python for the Director and Workers. I started in Go but returned to Python to focus on systems design over language learning. Pydantic handles request/response schemas; dataclasses model the domain logic.
The architecture follows Domain-Driven Design, using Repository and Service patterns (inspired by Cosmic Python).
Kafka handles job queues, PostgreSQL stores alert and job state, and everything is containerized with Docker. Kong Gateway CE will be used as an API gateway. Nix may be introduced later for reproducible builds. For low-level diagnostics, I’m deciding between libbpf, libbpf-rs or Cilium for eBPF integration.
LangChain for the AI Agents that I’m planning to add
Current State
This devlog reflects the long-term vision, but I’m still early in the process. Currently:
- Yubarta exposes an endpoint to receive Datadog alerts.
- Events are published to Kafka.
- The Director consumes them and persists them in Postgres.
The foundation is in place: components are containerized, key patterns scaffolded, and the core flow is working end-to-end.
Architecture
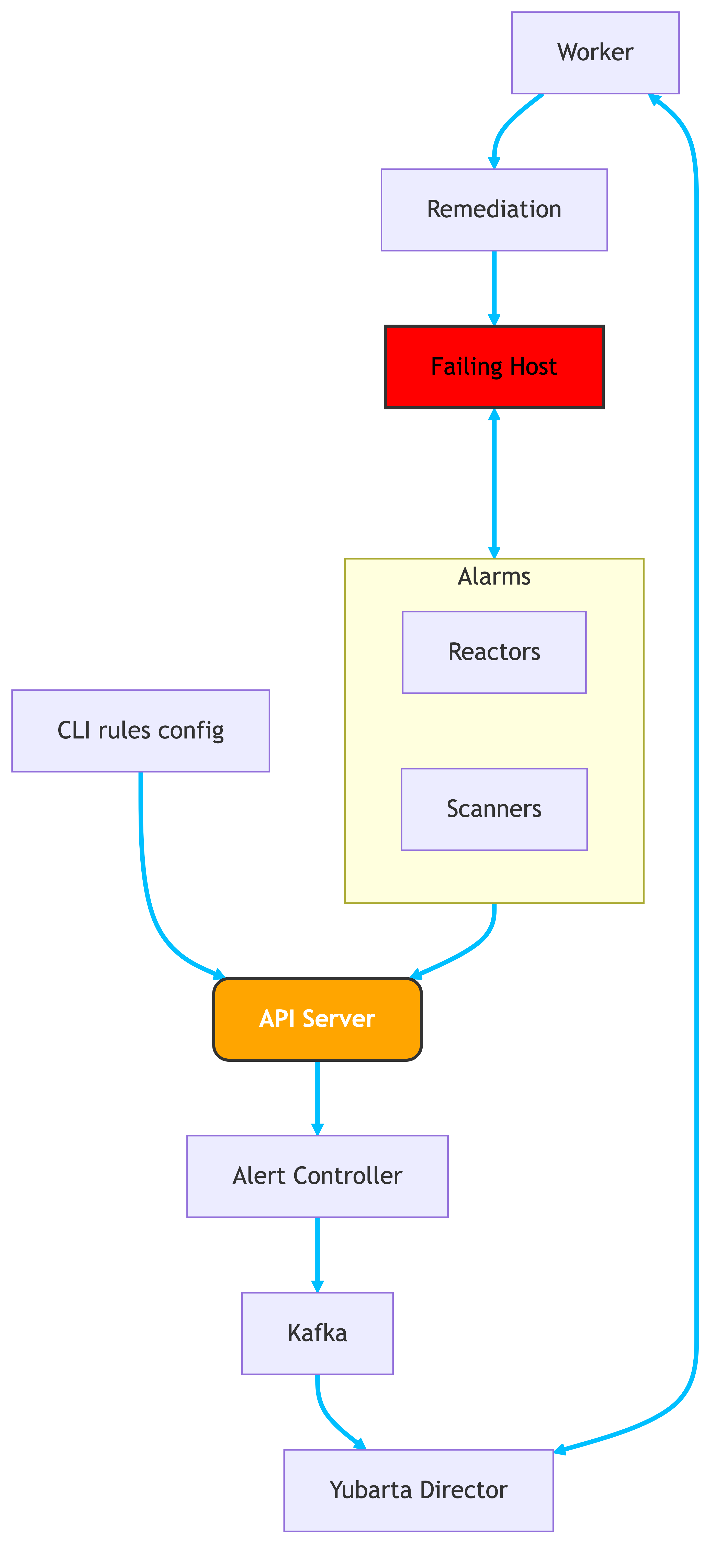
What’s Next
- Implement AI Agent.
- Build a YAML-defined job that runs a bpftrace script.
- Implement a CLI to inject and test profiling probes.
- Add Prometheus metrics for internal observability.
- Design the rule engine evaluation and sandboxing.
It’s still early, and I’m not sure if I’ll drop it soon or stick with it long-term — but right now, I’m excited about where it’s going.
🐋